Deep Bayesian Quadrature Policy Optimization
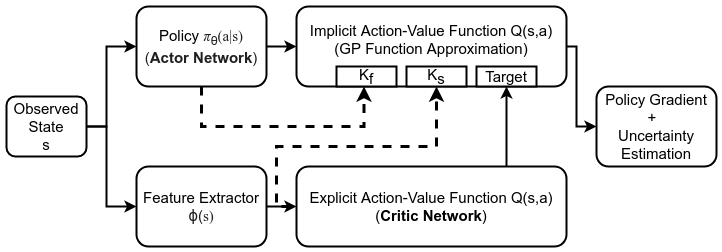
Abstract
We study the problem of obtaining accurate policy gradient estimates using a finite number of samples. Monte-Carlo methods have been the default choice for policy gradient estimation, despite suffering from high variance in the gradient estimates. On the other hand, more sample efficient alternatives like Bayesian quadrature methods are less scalable due to their high computational complexity. In this work, we propose deep Bayesian quadrature policy gradient (DBQPG), a computationally efficient high-dimensional generalization of Bayesian quadrature, for policy gradient estimation. We show that DBQPG can substitute Monte-Carlo estimation in policy gradient methods, and demonstrate its effectiveness on a set of continuous control benchmarks. In comparison to Monte-Carlo estimation, DBQPG provides (i) more accurate gradient estimates with a significantly lower variance, (ii) a consistent improvement in the sample complexity and average return for several deep policy gradient algorithms, and, (iii) the uncertainty in gradient estimation that can be incorporated to further improve the performance.
TL;DR
- We propose a new policy gradient estimator, deep Bayesian quadrature policy gradient (DBQPG), as an alternative to the predominantly used Monte-Carlo estimator. DBQPG provides more accurate gradient estimates with a significantly lower variance, quantifies the uncertainty in policy gradient estimation, and consistently offers a better performance for 3 policy gradient algorithms and across 7 MuJoCo environments.
- We also propose a new policy gradient method, uncertainty aware policy gradient (UAPG), that utilizes the quantified estimation uncertainty in DBQPG to compute reliable policy updates with robust step-sizes.
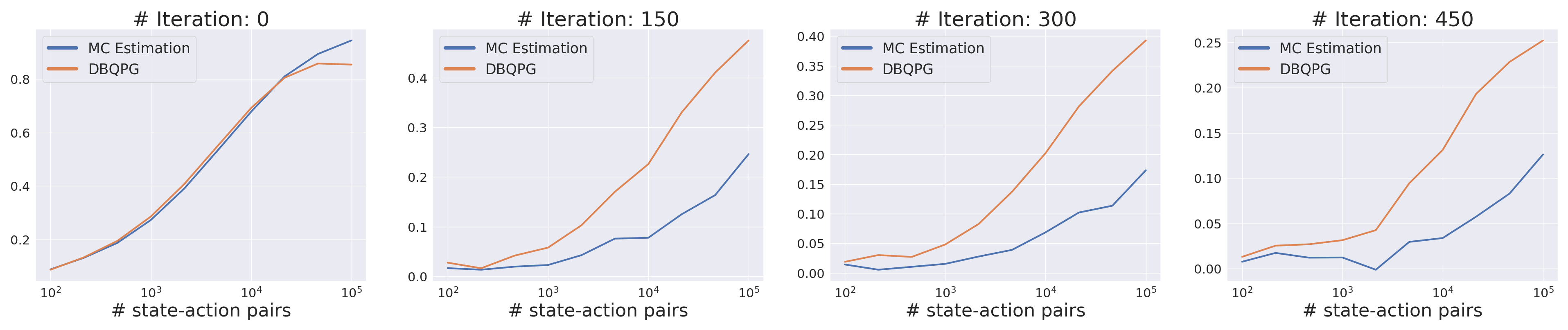
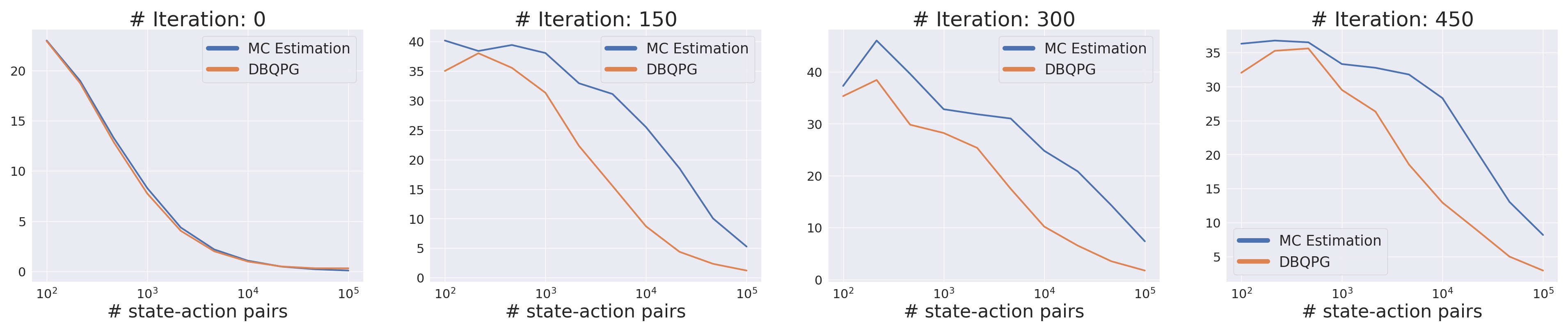
Quality of Gradient Estimation
1. Accuracy Plot (Gradient Cosine Similarity) :-
2. Variance Plot (Normalized Gradient Variance) :-
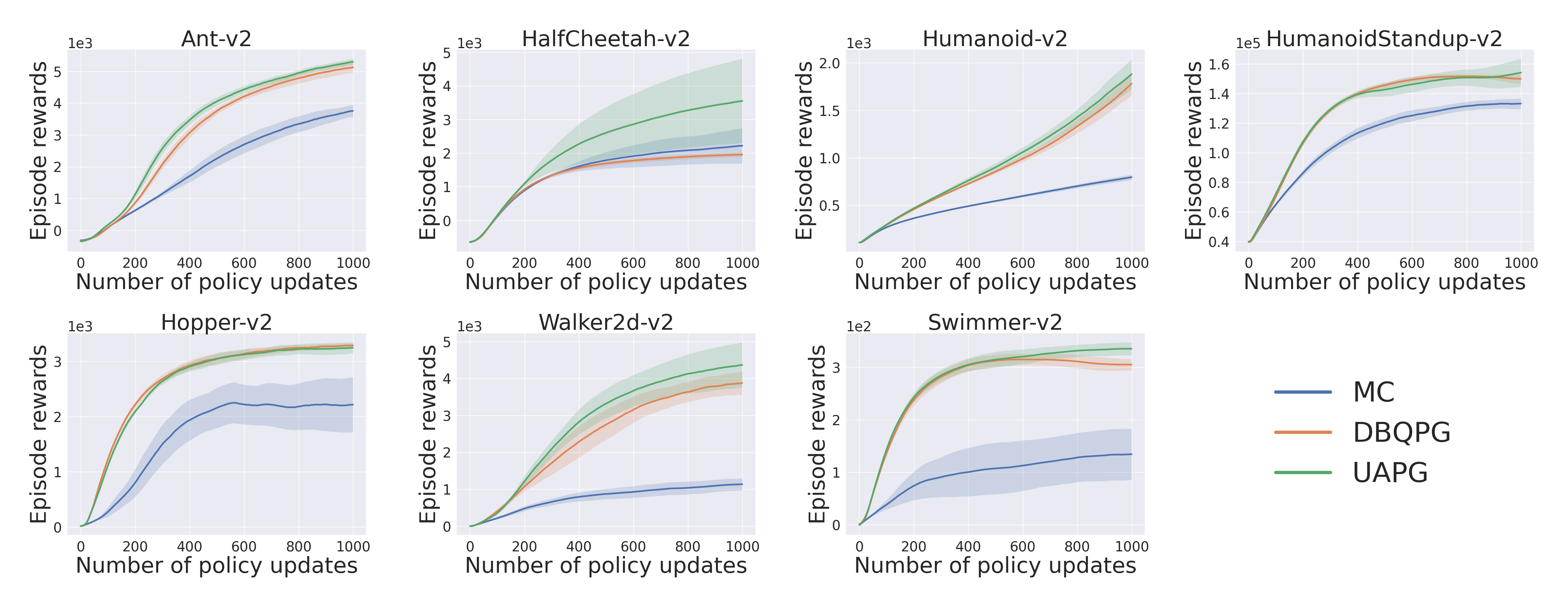
MuJoCo Experiments
1. Vanilla Policy Gradient :-
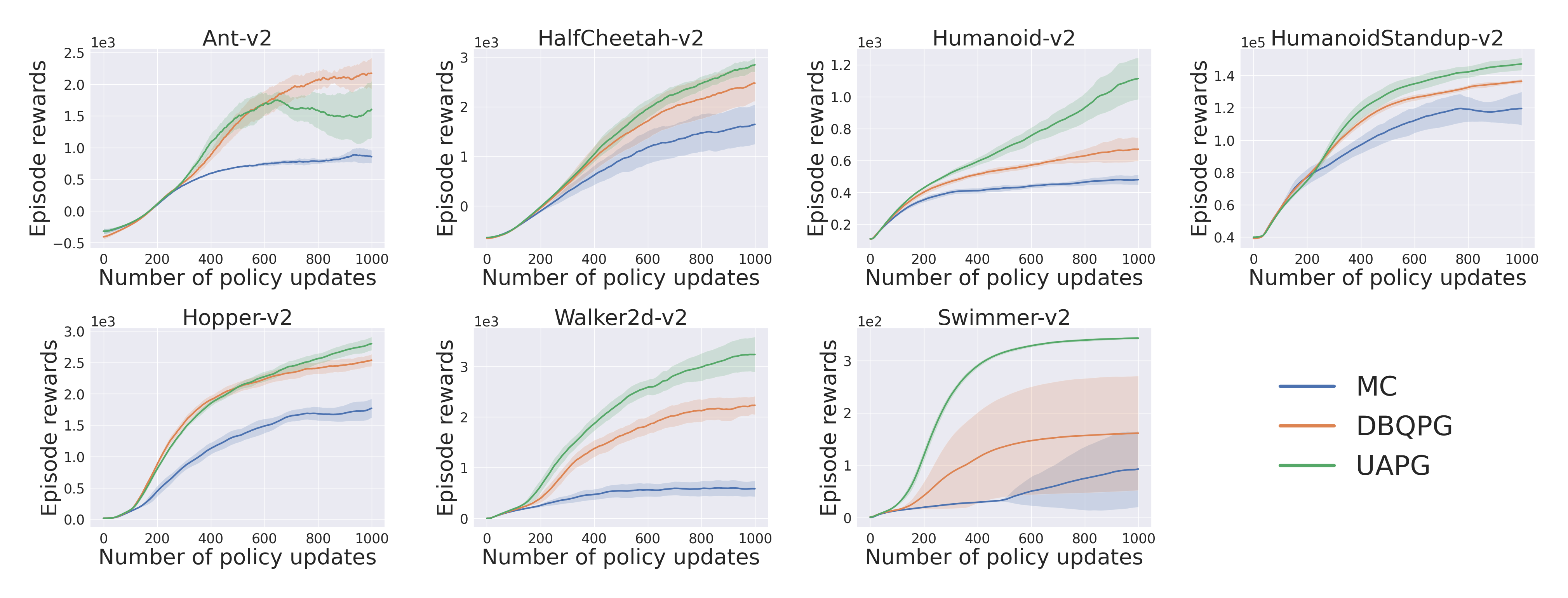
2. Natural Policy Gradient :-
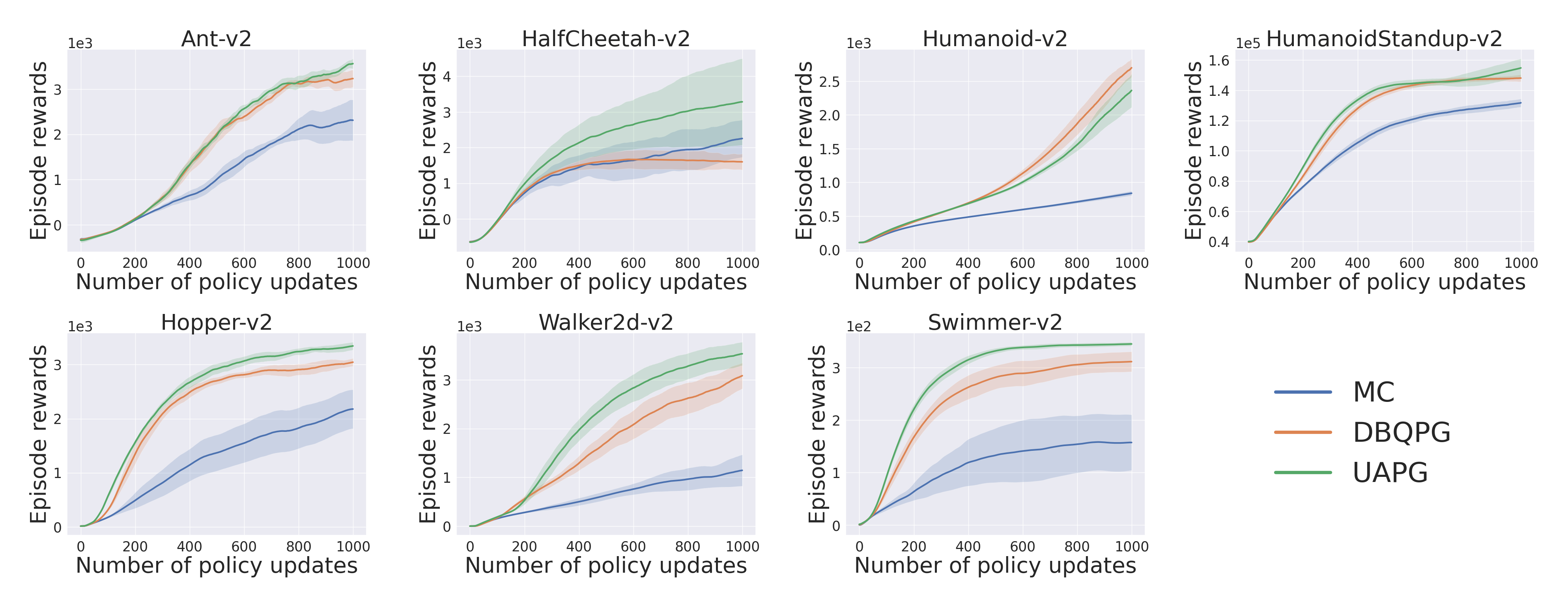
3. Trust Region Policy Optimization :-